Ever wondered how sometimes you are in your flow, listening to your favorite band and typing out great code in your choice of editor but then get interrupted by a pop-up dialog box that says , One of your open files has changed and needs to be reloaded. ?
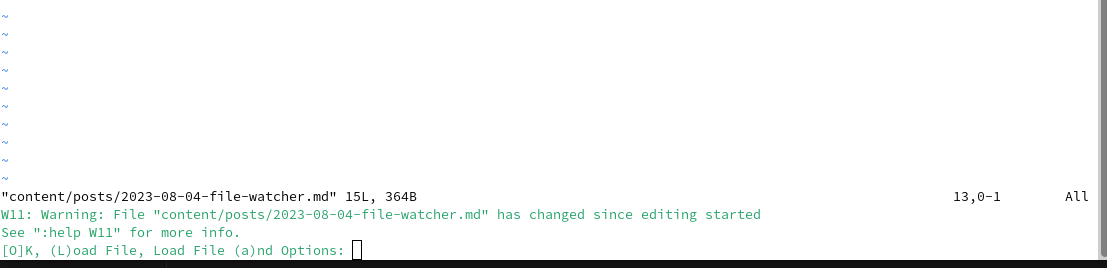
Or something like the image above if you simply had a file open in vim but the file somehow got updated through another medium.
May be this was a log file and instead of using tail you simply had opened it.
This is just one example of you encountering a notification pushed by a file-watching module of the said application.
Filewatchers can
- auto-reload files in local dev environment.
- trigger build processes, run tests, and deploy applications whenever changes are pushed to version control systems.
- synchronize files between two different locations ensuring changes get propagated in real-time or near-real-time.
- monitor log files or data streams to detect real-time events, enabling monitoring and alerting.
- back up and version files when changes are detected, helping to maintain data-integrity and prevent data-loss.
Uff, as a Software Engineer, all these sound like really cool functionalities to implement.
So today, we shall explore how something like this is actually implemented and can we write one ourselves (without using already available super-awesome libraries) ?
First let’s try to understand how this functionality is being achieved in a modern text/code editor.
Now would be a good time to narrow down the scope of our inquiry here to just end-user applications, since most Operating Systems employ their own native way to handle such notifications while doing tasks such as file indexing. We are interested in learning how an application keeps track of a file or a folder and notifies the user about a change.
If we try to envision the overall flow and try to break it down into major components, we would have things like:
-
File System Events:
Some event has to happen in order for our filewatcher application to do some work, events like create, modify, delete and move/rename. The application has to register with the Operating System to recieve such events on a given file/folder or continuously poll a provided OS specific API to find out. -
Operating System APIs:
The filewatcher app is generally going to interact with some underlying filesystem monitoring api offered by the OS. This usually differs from one os to another, for example inotify for Linux, fsevents for MacOS and ReadDirectoryChangesW for Windows. -
Event Handling:
You caught the event, now what ? There usually will be a event handling logic that needs to be defined. This is where a file watcher app would parse what kind of event has happened and take appropriate action and may or may not produce a notification about the change. The app might update some record in memory/persistent store, trigger a build or send notification to users. -
Polling vs Event-driven:
A filewatcher app usually employs either of the two approaches: polling or event-driven. Polling implies the filewatcher app will query the filesystem for changes at fixed-intervals. While this method works okay, it could easily become inefficient since continuous checking is required even when no changes occur.On the other hand, event-driven approach leverages the OS-provided APIs to receive real-time event notification thus reducing unnecessary overhead. -
Concurrency and Threading:
In the event-driven approach, file watchers often utilize concurrent programming or threading to handle multiple file system events simultaneously. This is essential to avoid blocking the main program’s execution while waiting for events. Proper synchronization mechanisms are used to ensure data integrity in multi-threaded environments. -
Debouncing and Throttling:
To prevent multiple events from being triggered for a single file system change, some file watchers employ debouncing or throttling mechanisms. Debouncing ensures that only one event is triggered for a series of rapid changes, whereas throttling limits the rate of events triggered within a specific time frame. Here is a good explanation for debouncing.
Entire academic papers are written on the topic but for now lets just move forward with a simple example. Lets say you are in a hurry and you press the channel-up button on your tv remote multiple times, faster than what your tv remote usually works with, a good debouncing circuit will simply ignore the multiple presses in a quick succession and only move channel up once. A bad debouncing circuit might cause a single button press to jump the channel twice.
We have the components decoded, lets figure out some form of a basic algorithm now.
- Start with monitoring the file system for a given filepath.
- Wait for any filesystem events (such as creation, modifications, deletions or renames.)
- When a filesystem event occurs, filewatcher receives the event notification from the Operating Sytem’s monitoring api.
- Event handling component processes the event. Performs actions based on the event type.
- The filewatcher updates the list of files to watch appropriately after the loop.
Lets convert the algorithm so far into pseudo-code
function file_watcher(path_to_watch):
# Initialize a set to store the initial state of the directory
files_in_directory = get_files_in_directory(path_to_watch)
# Start the file watcher loop
while True:
# Wait for a file system event to occur
event = wait_for_file_event()
# Get the current state of the directory
current_files = get_files_in_directory(path_to_watch)
# Check for new or modified files
for file_name in current_files - files_in_directory:
handle_file_created_or_modified(file_name)
# Check for deleted files
for file_name in files_in_directory - current_files:
handle_file_deleted(file_name)
# Update the state of the directory
files_in_directory = current_files
function get_files_in_directory(path):
# Use the appropriate OS function to get a list of files in the directory
# Return the list of file names
...
function wait_for_file_event():
# Use the appropriate OS function to wait for a file system event
# Return the event object
...
function handle_file_created_or_modified(file_name):
# Handle the file creation or modification event
# This could involve reading the file, updating application data, etc.
...
function handle_file_deleted(file_name):
# Handle the file deletion event
# This could involve removing the file from application data, etc.
...
this should be quite self-explanatory.
Implementation
main.go listing
package main
import (
"fmt"
"os"
"path/filepath"
"time"
)
func watchDirectory(pathToWatch string) {
// store the initial state of the directory in a map
filesInDirectory := getFilesInDirectory(pathToWatch)
for {
time.Sleep(1 * time.Second) // Adjust the interval as needed
// Get the current state of the directory
currentFiles := getFilesInDirectory(pathToWatch)
// Check for new or modified files
for file := range difference(currentFiles, filesInDirectory) {
handleFileCreatedOrModified(file)
}
// Check for deleted files
for file := range difference(filesInDirectory, currentFiles) {
handleFileDeleted(file)
}
// Update the state of the directory
filesInDirectory = currentFiles
}
}
func getFilesInDirectory(path string) map[string]bool {
files := make(map[string]bool)
err := filepath.Walk(path, func(path string, info os.FileInfo, err error) error {
if err != nil {
return err
}
// Skip directories
if info.IsDir() {
return nil
}
files[path] = true
return nil
})
if err != nil {
fmt.Println("Error reading directory:", err)
}
return files
}
func handleFileCreatedOrModified(fileName string) {
// Handle the file creation or modification event
// This could involve reading the file, updating application data, etc.
fmt.Println("File created or modified:", fileName)
}
func handleFileDeleted(fileName string) {
// Handle the file deletion event
// This could involve removing the file from application data, etc.
fmt.Println("File deleted:", fileName)
}
func difference(a, b map[string]bool) map[string]bool {
result := make(map[string]bool)
for k := range a {
if !b[k] {
result[k] = true
}
}
return result
}
func main() {
directoryToWatch := "./testDir"
watchDirectory(directoryToWatch)
}
You can find the full code on github at this link filewatcher
Wrap
That’s all folks, hope this helped you in some form towards learning how a file watcher works.
Now go out, explore the existing popular opensource filewatcher apps like
these are more well thought-out, have cross-platform support, handle a lot of edge-cases and are maintained by several very-smart folks. But hopefully with the intrinsic knowledge of how a filewatcher works in a general sense, the complexity wont deter us in understanding and contributing to these.